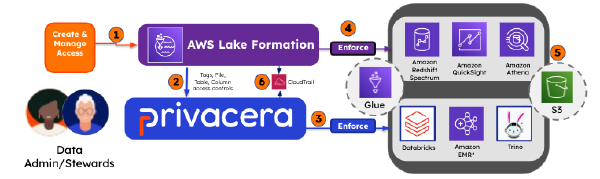
Many organizations are using AWS Lake Formation to manage data security and access management for Amazon Athena, Amazon Redshift Spectrum, or Presto with Amazon EMR, but they want to be able to manage other sources with a single central data security platform. Thus, allowing organizations to apply consistent and un-siloed data security and access policies across all their data sources, reduce the effort required to manage data security and access policies, make data more accessible, and enhance their security posture.
A modern data strategy is a comprehensive plan for how you manage, access, analyze, and act on data. Most companies are already building roadmaps toward that goal, but the gap between “we have a plan” and “we’re getting value from our data” can be significant.
This session covers how deploying a modern data architecture on AWS helps close that gap — navigating common data challenges, streamlining analytics processes, and getting to business insights faster. We take a closer look at AWS Glue and AWS Lake Formation specifically, and how they accelerate the journey.
One of the hardest things in product is articulating your organization’s unique ability to deliver value to its market. It’s also one of the most important. So how do you build a path that combines innovation, proven methodology, and practical approaches to identify the attributes and differentiators that set you apart from your competitors?
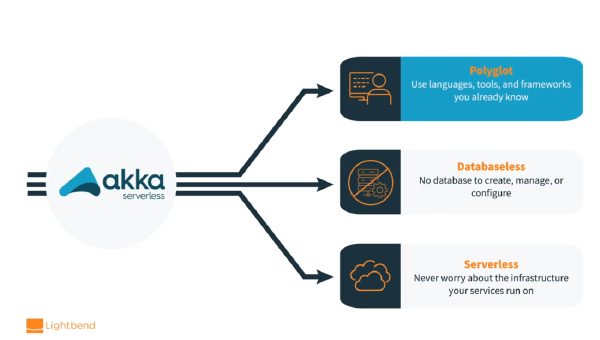
One of the things I love about serverless is that I never have to be bothered with managing servers, it’s just using a service like Lambda, Cloud Run, etc and my code is running. If I want to use a database I can rely on services like DynamoDB or CosmosDB. While I think that is absolutely great, it feels like serverless is only for stateless processes. I think serverless needs a bold and stateful vision so that we can build any type of application (stateful and stateless) without ever managing servers. In this talk, I’ll touch on why statefulness matters and how stateful serverless makes patterns like Event Sourcing and CQRS available to anyone.
In the session I went over why serverless is important to our industry, why server admins (which I then rephrased to SREs) are so important to our serverless success, and why stateless isn’t the answer for everything. Technology wise I’ll be “all over the map” talking about things like Knative and the VMware Event Broker Appliance, AWS Lambda, Akka Serverless
Leon Stigter, senior product manager for serverless at Lightbend, explained the core problem to SiliconANGLE: developers generally think of serverless as a “stateless solution,” meaning every time an application needs to do something, it has to connect to a database first. For a single service that’s manageable, but at scale, things like connection pooling get painful fast.
As Auth0 says on their website “Identity is the front door of every user interaction”. When you’re building serverless applications, that becomes even more important since you often have multiple apps that all need to be secured. In this post I’ll walk you through how to wire up Auth0 with Akka Serverless.
CI/CD is one of those things that pays for itself almost immediately. In serverless especially, where the whole point is to focus on code and let the platform handle the rest, automating your deployment pipeline is a no-brainer. It lets developers focus on code and lets the business ship quality software faster. So how does that work with Akka Serverless?
As developers, we all want to be more productive. Serverless helps you do just that, by letting you focus on the business logic while shifting operations somewhere else. As more companies discover this emerging technology, we also discover drawbacks like state management. In this session, I focused on what serverless is, how it helps developers, what potential drawbacks exist, and how we can add state management into serverless.